
I am doing research in machine learning, computer vision and robotics at the Amazon Research and Development Center in Berlin. You can find more information about me here.
News
- 11/01/2019 - PAMI paper on RefineNet accepted.
- 21/12/2018 - We will hold another MOTChallenge Workshop at CVPR 2019 in Los Angeles.
- 19/02/2018 - PoseTrack paper accepted to CVPR.
- 15/01/2018 - Two ICRA papers accepted on ARC system and perception.
- 09/11/2017 - AAAI'18 paper accepted.
- 15/08/2017 - I joined the Amazon Core Machine Learning Group in Berlin.
- 30/07/2017 - Our team won the Final Round at the Amazon Robotics Challenge.
Publications
See also Google Scholar
2019
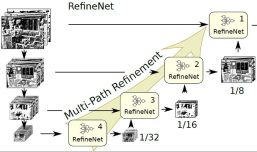
RefineNet: Multi-Path Refinement Networks
for Dense Prediction
G. Lin,
F. Liu,
A. Milan,
C. Shen,
I. Reid.
In PAMI 2019
bibtex |
abstract |
paper |
code
@article{Lin:2019:PAMI,
Author = {Lin, G. and Liu, F. and Milan, A. and Shen, C. and Reid, I.},
Title = {Refine{N}et: {M}ulti-Path Refinement Networks for Dense Prediction},
volume = {41},
number = {1},
month={Jan},
pages={1-1},
doi={10.1109/TPAMI.2019.2893630},
journal = {IEEE TPAMI},
year = {2019}
}
Recently, very deep convolutional neural networks (CNNs) have shown outstanding performance in object recognition and have also been the first choice for dense prediction problems such as semantic segmentation and depth estimation. However, repeated sub-sampling operations like pooling or convolution striding in deep CNNs lead to a significant decrease in the initial image resolution. Here, we present RefineNet, a generic multi-path refinement network that explicitly exploits all the information available along the down-sampling process to enable high-resolution prediction using long-range residual connections. In this way, the deeper layers that capture high-level semantic features can be directly refined using fine-grained features from earlier convolutions. The individual components of RefineNet employ residual connections following the identity mapping mindset, which allows for effective end-to-end training. Further, we introduce chained residual pooling, which captures rich background context in an efficient manner. We carry out comprehensive experiments on semantic segmentation which is a dense classification problem and set new state-of-the-art results on seven public datasets. We further apply our method for depth estimation and demonstrate the effectiveness of our method on dense regression problems.
2018
PoseTrack: A Benchmark for Human Pose Estimation and Tracking
Iqbal, U. and Milan, A. and Andriluka, M. and Ensafutdinov, E. and Pishchulin, L. and Gall, J. and Schiele B.
In CVPR 2018
bibtex |
abstract |
paper |
@inproceedings{PoseTrack,
Title = {Pose{T}rack: {A} Benchmark for Human Pose Estimation and Tracking},
booktitle = {CVPR},
Author = {Iqbal, U. and Milan, A. and Andriluka, M. and Ensafutdinov, E. and Pishchulin, L. and Gall, J. and Schiele B.},
Year = {2018}
}
Human poses and motions are important cues for analysis of videos with people and there is strong evidence that representations based on body pose are highly effective for a variety of tasks such as activity recognition, content retrieval and social signal processing. In this work, we aim to further advance the state of the art by establishing "PoseTrack" , a new large-scale benchmark for video-based human pose estimation and articulated tracking, and bringing together the community of researchers working on visual human analysis. The benchmark encompasses three competition tracks focusing on i) single-frame multi-person pose estimation, ii) multi-person pose estimation in videos, and iii) multi-person articulated tracking. To facilitate the benchmark and challenge we collect, annotate and release a new %large-scale benchmark dataset that features videos with multiple people labeled with person tracks and articulated pose. A centralized evaluation server is provided to allow participants to evaluate on a held-out test set. We envision that the proposed benchmark will stimulate productive research both by providing a large and representative training dataset as well as providing a platform to objectively evaluate and compare the proposed methods. The benchmark is freely accessible at posetrack.net.
Semantic Segmentation from Limited Training Data
A. Milan et al.
In ICRA 2018
bibtex |
abstract |
paper |
video
@inproceedings{Milan:2018:ICRA,
Title = {Semantic Segmentation from Limited Training Data},
Booktitle = {ICRA}
Author = {Milan, A. and Pham, T. and Vijay, K. and Morrison, D and Tow, A. W. and Liu, L. and
Erskine, J. and Grinover, R. and Gurman, A. and Hunn, T. and Kelly-Boxall, N. and Lee, D. and
McTaggart, M. and Rallos, G. and Razjigaev, A. and Rowntree, T. and Shen T. and Smith, R. and
Wade-McCue, S. and Zhuang, Z. and Lehnert, C. and Lin, G. and Reid, I. and Corke, P. and Leitner, J.},
Month = {May},
Year = {2018}
}
We present our approach for robotic perception in cluttered scenes that led to winning the recent Amazon Robotics Challenge (ARC) 2017. Next to small objects with shiny and transparent surfaces, the biggest challenge of the 2017 competition was the introduction of unseen categories. In contrast to traditional approaches which require large collections of annotated data and many hours of training, the task here was to obtain a robust perception pipeline with only few minutes of data acquisition and training time. To that end, we present two strategies that we explored. One is a deep metric learning approach that works in three separate steps: semantic-agnostic boundary detection, patch classification and pixel-wise voting. The other is a fully-supervised semantic segmentation approach with efficient dataset collection. We conduct an extensive analysis of the two methods on our ARC 2017 dataset. Interestingly, only few examples of each class are sufficient to fine-tune even very deep convolutional neural networks for this specific task.

Cartman: The low-cost Cartesian Manipulator that won the Amazon Robotics Challenge
D. Morrison et al.
In ICRA 2018
bibtex |
abstract |
paper |
video
@inproceedings{Morrison:2018:ICRA,
Title = {Cartman: {T}he low-cost Cartesian Manipulator that won the {A}mazon {R}obotics {C}hallenge},
booktitle = {ICRA}
Author = {Morrison, D. and others},
month = {May},
year = {2018}
}
The Amazon Robotics Challenge enlisted sixteen teams to each design a pick-and-place robot for autonomous warehousing, addressing development in robotic vision and manipulation. This paper presents the design of our custom-built. cost-effective robot system Cartman, which won first place in the competition finals by stowing 14 (out of 16) and picking all 9 items in 27 minutes, scoring a total of 272 points. We highlight our experience- centred design methodology and key aspects of our system that contributed to our competitiveness. We believe these aspects are crucial to building robust and effective robotic systems.
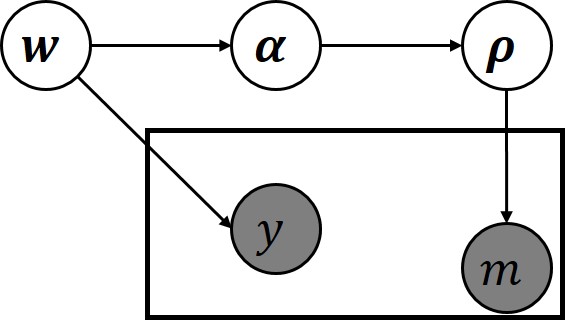
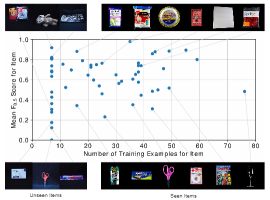
Joint Learning of Set Cardinality and State Distribution
S. H. Rezatofighi,
A. Milan,
Q. Shi,
A. Dick,
I. Reid.
In AAAI
bibtex |
abstract |
paper |
@inproceedings{Rezatofighi:2018:JDS,
Title = {Joint Learning of Set Cardinality and State Distribution},
url = {https://arxiv.org/abs/1709.04093},
booktitle = {AAAI},
Author = {Rezatofighi, S. H. and Milan, A. and Shi, Q. and Dick, A. and Reid, I.},
Year = {2018}
}
We present a novel approach for learning to predict sets using deep learning. In recent years, deep neural networks have shown remarkable results in computer vision, natural language processing and other related problems. Despite their success, traditional architectures suffer from a serious limitation in that they are built to deal with structured input and output data, i.e. vectors or matrices. Many real-world problems, however, are naturally described as sets, rather than vectors. Existing techniques that allow for sequential data, such as recurrent neural networks, typically heavily depend on the input and output order and do not guarantee a valid solution. Here, we derive in a principled way, a mathematical formulation for set prediction which is permutation invariant. In particular, our approach jointly learns both the cardinality and the state distribution of the target set. We demonstrate the validity of our method on the task of multi-label image classification and achieve a new state of the art on the PASCAL VOC and MS COCO datasets.
2017

DeepSetNet: Predicting Sets with Deep Neural Networks
S. H. Rezatofighi,
V. Kumar,
A. Milan,
E. Abbasnejad,
A. Dick,
I. Reid.
In ICCV 2017
bibtex |
abstract |
paper |
demo
@inproceedings{Rezatofighi:2017:ICCV,
Title = {Deep{S}et{N}et: {P}redicting Sets with Deep Neural Networks},
shorttitle = {DeepSetNet},
url = {https://arxiv.org/abs/1611.08998},
Author = {Rezatofighi, S. H. and Kumar BG, V. and Milan, A. and Abbasnejad, E. and Dick, A. and Reid, I.},
Booktitle = {ICCV},
Year = {2017}
}
This paper addresses the task of set prediction using deep learning. This is important because the output of many computer vision tasks, including image tagging and object detection, are naturally expressed as sets of entities rather than vectors. As opposed to a vector, the size of a set is not fixed in advance, and it is invariant to the ordering of entities within it. We define a likelihood for a set distribution and learn its parameters using a deep neural network. We also derive a loss for predicting a discrete distribution corresponding to set cardinality. Set prediction is demonstrated on the problems of multi-class image classification and pedestrian detection. Our approach yields state-of-the-art results in both cases on standard datasets.

Multi-class RGB-D Object Detection and Semantic Segmentation for Autonomous Manipulation in Clutter
M. Schwarz,
A. Milan,
A. S. Periyasamy,
S. Behnke.
Accepted to IJRR
bibtex |
abstract
@article{Schwarz:2017:IJRR,
title = {Multi-class RGB-D Object Detection and Semantic Segmentation for Autonomous Manipulation in Clutter},
booktitle = {IJRR},
author = {Schwarz, M. and Milan, A. and Periyasamy A. S. and Behnke S.},
volume = {37},
number = {4-5},
month = {Jun},
year = {2017}
}
Autonomous robotic manipulation in clutter is challenging. A large variety of objects must be perceived in complex scenes, where they are partially occluded and embedded among many distractors, often in restricted spaces. To tackle these challenges, we developed a deep-learning approach that combines object detection and semantic segmentation. The manipulation scenes are captured with RGB-D cameras, for which we developed a depth fusion method. Employing pretrained features makes learning from small annotated robotic data sets possible. We evaluate our approach on two challenging data sets: one captured for the Amazon Picking Challenge 2016, where our team NimbRo came in second in the Stowing and third in the Picking task, and one captured in disaster-response scenarios. The experiments show that object detection and semantic segmentation complement each other and can be combined to yield reliable object perception.
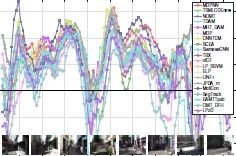
Tracking the Trackers:
An Analysis of the State of the Art in Multiple Object Tracking
L. Leal-Taixé,
A. Milan,
K. Schindler,
D. Cremers,
I. Reid,
S. Roth
arXiv:1704.02781
bibtex |
abstract |
paper
@article{2017:Leal:arxiv,
title = {Tracking the Trackers: {A}n Analysis of the State of the Art in Multiple Object Tracking},
shorttitle = {Tracking the Trackers},
url = {http://arxiv.org/abs/1704.02781},
journal = {arXiv:1704.02781 [cs]},
author = {Leal-Taix\'{e}, Laura and Milan, Anton and Schindler, Konrad and Cremers, Daniel and Reid, Ian and Roth, Stefan},
month = apr,
year = {2017},
note = {arXiv: 1704.02781},
keywords = {Computer Science - Computer Vision and Pattern Recognition}
}
Standardized benchmarks are crucial for the majority of computer vision applications. Although leaderboards and ranking tables should not be over-claimed, benchmarks often provide the most objective measure of performance and are therefore important guides for research. We present a benchmark for Multiple Object Tracking launched in the late 2014, with the goal of creating a framework for the standardized evaluation of multiple object tracking methods. This paper collects the two releases of the benchmark made so far, and provides an in-depth analysis of almost 50 state-of-the-art trackers that were tested on over 11000 frames. We show the current trends and weaknesses of multiple people tracking methods, and provide pointers of what researchers should be focusing on to push the field forward.
RefineNet: Multi-Path Refinement Networks
for High-Resolution Semantic Segmentation
G. Lin,
A. Milan,
C. Shen,
I. Reid.
In CVPR 2017
bibtex |
abstract |
paper |
code
@inproceedings{Lin:2017:CVPR,
Author = {Lin, G. and Milan, A. and Shen, C. and Reid, I.},
Title = {Refine{N}et: {M}ulti-Path Refinement Networks for High-Resolution Semantic Segmentation},
Booktitle = {CVPR},
Year = {2017}
}
Recently, very deep convolutional neural networks (CNNs) have shown outstanding performance in object recognition and have also been the first choice for dense classification problems such as semantic segmentation. However, repeated subsampling operations like pooling or convolution striding in deep CNNs lead to a significant decrease in the initial image resolution. Here, we present RefineNet, a generic multi-path refinement network that explicitly exploits all the information available along the down-sampling process to enable high-resolution prediction using long-range residual connections. In this way, the deeper layers that capture high-level semantic features can be directly refined using fine-grained features from earlier convolutions. The individual components of RefineNet employ residual connections following the identity mapping mindset, which allows for effective end-to-end training. Further, we introduce chained residual pooling, which captures rich background context in an efficient manner. We carry out comprehensive experiments and set new state-of-the-art results on seven public datasets. In particular, we achieve an intersection-over-union score of 83.4 on the challenging PASCAL VOC 2012 dataset, which is the best reported result to date.

PoseTrack: Joint Multi-Person Pose Estimation and Tracking
U. Iqbal,
A. Milan,
J. Gall.
In CVPR 2017
bibtex |
abstract |
paper |
project
@inproceedings{Iqbal:2017:CVPR,
Author = {Iqbal, U. and Milan, A. and Gall, J.},
Title = {Pose{T}rack: {J}oint Multi-Person Pose Estimation and Tracking},
Booktitle = {CVPR},
Year = {2017}
}
In this work, we introduce the challenging problem of joint multi-person pose estimation and tracking of an unknown number of persons in unconstrained videos. Existing methods for multi-person pose estimation in images cannot be applied directly to this problem, since it also requires to solve the problem of person association over time in addition to the pose estimation for each person. We therefore propose a novel method that jointly models multi-person pose estimation and tracking in a single formulation. To this end, we represent body joint detections in a video by a spatio-temporal graph and solve an integer linear program to partition the graph into sub-graphs that correspond to plausible body pose trajectories for each person. The proposed approach implicitly handles occlusions and truncations of persons. Since the problem has not been addressed quantitatively in the literature, we introduce a challenging "Multi-Person Pose-Track" dataset, and also propose a completely unconstrained evaluation protocol that does not make any assumptions on the scale, size, location or the number of persons. Finally, we evaluate the proposed approach and several baseline methods on our new dataset.

NimbRo Picking: Versatile Part Handling for Warehouse Automation
M. Schwarz,
A. Milan,
C. Lenz,
A. Muñoz,
A. S. Periyasamy,
M. Schreiber,
S. Schüller,
S. Behnke.
In ICRA 2017
bibtex |
abstract |
paper
@inproceedings{Schwarz:2017:ICRA,
title = {Nimb{R}o {P}icking: {V}ersatile Part Handling for Warehouse Automation},
booktitle = {ICRA},
author = {Schwarz, M. and Milan, A. and Lenz C. and Mu{\~n}oz A. and Periyasamy A. S. and Schreiber M. and Sch{\"u}ller S. and Behnke S.},
month = {June},
year = {2017}
}
Part handling in warehouse automation is challenging if a large variety of items must be accommodated and items are stored in unordered piles. To foster research in this domain, Amazon holds picking challenges. We present our system which achieved second and third place in the Amazon Picking Challenge 2016 tasks. The challenge required participants to pick a list of items from a shelf or to stow items into the shelf. Using two deep-learning approaches for object detection and semantic segmentation and one item model registration method, our system localizes the requested item. Manipulation occurs using suction on points determined heuristically or from 6D item model registration. Parametrized motion primitives are chained to generate motions. We present a full-system evaluation during the APC 2016 and component level evaluations of the perception system on an annotated dataset.
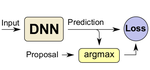
Data-Driven Approximations to NP-Hard Problems
A. Milan,
S. H. Rezatofighi,
R. Garg,
A. Dick,
I. Reid.
In AAAI 2017
bibtex |
abstract |
paper |
slides |
code
@inproceedings{Milan:2017:AAAI_NP,
title = {Data-driven approximations to {NP}-hard problems},
booktitle = {AAAI},
author = {Milan, A. and Rezatofighi, S. H. and Garg, R. and Dick, A. and Reid, I.},
month = {February},
year = {2017}
}
There exist a number of problem classes, for which obtaining the exact solution becomes exponentially expensive with increasing problem size. The quadratic assignment problem (QAP) or the travelling salesman problem (TSP) are just two examples of such NP-hard problems. In practice, approximate algorithms are employed to obtain a suboptimal solution, where one must face a trade-off between computational complexity and solution quality. In this paper, we propose to learn to solve these problem from approximate examples, using recurrent neural networks (RNNs). Surprisingly, such architectures are capable of producing highly accurate solutions at minimal computational cost. Moreover, we introduce a simple, yet effective technique for improving the initial (weak) training set by incorporating the objective cost into the training procedure. We demonstrate the functionality of our approach on three exemplar applications: marginal distributions of a joint matching space, feature point matching and the travelling salesman problem. We show encouraging results on synthetic and real data in all three cases.
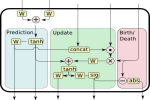
Online Multi-Target Tracking Using Recurrent Neural Networks
A. Milan,
S. H. Rezatofighi,
A. Dick,
I. Reid,
K. Schindler
In AAAI 2017
bibtex |
abstract |
paper |
poster |
code
@inproceedings{Milan:2017:AAAI_RNNTracking,
title = {Online Multi-Target Tracking using Recurrent Neural Networks},
booktitle = {AAAI},
author = {Milan, A. and Rezatofighi, S. H. and Dick, A. and Reid, I. and Schindler, K.},
month = {February},
year = {2017}
}
We present a novel approach to online multi-target tracking based on recurrent neural networks (RNNs). Tracking multiple objects in real-world scenes involves many challenges, including a) an a-priori unknown and time-varying number of targets, b) a continuous state estimation of all present targets, and c) a discrete combinatorial problem of data association. Most previous methods involve complex models that require tedious tuning of parameters. Here, we propose for the first time, a full end-to-end learning approach for online multi-target tracking based on deep learning. Existing deep learning methods are not designed for the above challenges and cannot be trivially applied to the task. Our solution addresses all of the above points in a principled way. Experiments on both synthetic and real data show competitive results obtained at 300 Hz on a standard CPU, and pave the way towards future research in this direction.
2016
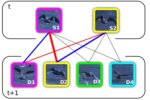
Joint Probabilistic Matching Using m-Best Solutions
S. H. Rezatofighi,
A. Milan,
Z. Zhang,
A. Dick,
Q. Shi,
I. Reid
CVPR 2016 (oral presentation)
bibtex |
abstract |
paper |
supplemental |
slides |
poster |
video |
project
@inproceedings{Rezatofighi:2016:CVPR,
Author = {Rezatofighi, S. H. and Milan, A. and Zhang, Z. and Shi, Q. and Dick, A. and Reid, I.},
Booktitle = {CVPR},
Title = {Joint Probabilistic Matching Using m-Best Solutions},
Year = {2016}
}
Matching between two sets of objects is typically ap- proached by finding the object pairs that collectively maxi- mize the joint matching score. In this paper, we argue that this single solution does not necessarily lead to the opti- mal matching accuracy and that general one-to-one assign- ment problems can be improved by considering multiple hy- potheses before computing the final similarity measure. To that end, we propose to utilize the marginal distributions for each entity. Previously, this idea has been neglected mainly because exact marginalization is intractable due to a com- binatorial number of all possible matching permutations. Here, we propose a generic approach to efficiently approx- imate the marginal distributions by exploiting the m-best solutions of the original problem. This approach not only improves the matching solution, but also provides more ac- curate ranking of the results, because of the extra informa- tion included in the marginal distribution. We validate our claim on two distinct objectives: (i) person re-identification and temporal matching modeled as an integer linear pro- gram, and (ii) feature point matching using a quadratic cost function. Our experiments confirm that marginalization in- deed leads to superior performance compared to the single (nearly) optimal solution, yielding state-of-the-art results in both applications on standard benchmarks.

MOT16: A Benchmark for Multi-Object Tracking
A. Milan,
L. Leal-Taixé,
I. Reid,
S. Roth, and
K. Schindler
arXiv:1603.00831
bibtex |
abstract |
paper |
project page
@article{MOT16,
title = {{MOT}16: {A} Benchmark for Multi-Object Tracking},
shorttitle = {MOT16},
url = {http://arxiv.org/abs/1603.00831},
journal = {arXiv:1603.00831 [cs]},
author = {Milan, A. and Leal-Taix\'{e}, L. and Reid, I. and Roth, S. and Schindler, K.},
month = mar,
year = {2016},
note = {arXiv: 1603.00831},
keywords = {Computer Science - Computer Vision and Pattern Recognition}
}
Standardized benchmarks are crucial for the majority of computer vision applications. Although leaderboards and ranking tables should not be over-claimed, benchmarks often provide the most objective measure of performance and are therefore important guides for reseach. Recently, a new benchmark for Multiple Object Tracking, MOTChallenge, was launched with the goal of collecting existing and new data and creating a framework for the standardized evaluation of multiple object tracking methods. The first release of the benchmark focuses on multiple people tracking, since pedestrians are by far the most studied object in the tracking community. This paper accompanies a new release of the MOTChallenge benchmark. Unlike the initial release, all videos of MOT16 have been carefully annotated following a consistent protocol. Moreover, it not only offers a significant increase in the number of labeled boxes, but also provides multiple object classes beside pedestrians and the level of visibility for every single object of interest.
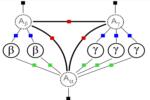
Multi-Target Tracking by Discrete-Continuous Energy Minimization
A. Milan,
K. Schindler and
S. Roth
PAMI 38(1), 2016
bibtex |
abstract |
paper |
video
 |
project page
|
project page
@article{Milan:2016:PAMI,
author = {Milan, A. and Schindler, K. and Roth, S.},
title = {Multi-Target Tracking by Discrete-Continuous Energy Minimization},
volume = {38},
number = {10},
month={Oct},
pages={2054-2068},
doi={10.1109/TPAMI.2015.2505309},
journal = {IEEE TPAMI},
year = {2016}
}
The task of tracking multiple targets is often addressed with the so-called tracking-by-detection paradigm, where the first step is to obtain a set of target hypotheses for each frame independently. Tracking can then be regarded as solving two separate, but tightly coupled problems. The first is to carry out data association, i.e. to determine the origin of each of the available observations. The second problem is to reconstruct the actual trajectories that describe the spatio-temporal motion pattern of each individual target. The former is inherently a discrete problem, while the latter should intuitively be modeled in continuous space. Having to deal with an unknown number of targets, complex dependencies, and physical constraints, both are challenging tasks on their own and thus most previous work focuses on one of these subproblems. Here, we present a multi-target tracking approach that explicitly models both tasks as minimization of a unified discrete-continuous energy function. Trajectory properties are captured through global label costs, a recent concept from multi-model fitting, which we introduce to tracking. Specifically, label costs describe physical properties of individual tracks, e.g. linear and angular dynamics, or entry and exit points. We further introduce pairwise label costs to describe mutual interactions between targets in order to avoid collisions. By choosing appropriate forms for the individual energy components, powerful discrete optimization techniques can be leveraged to address data association, while the shapes of individual trajectories are updated by gradient-based continuous energy minimization. The proposed method achieves state-of-the-art results on diverse benchmark sequences.
2015

Joint Probabilistic Data Association Revisited
S. H. Rezatofighi,
A. Milan,
Z. Zhang,
A. Dick,
Q. Shi,
I. Reid
ICCV 2015
bibtex |
abstract |
paper |
code |
video 1
video 2
@inproceedings{Rezatofighi:2015:ICCV,
Author = {Rezatofighi, S. H. and Milan, A. and Zhang, Z. and Shi, Q. and Dick, A. and Reid, I.},
Booktitle = {ICCV},
Title = {Joint Probabilistic Data Association Revisited},
Year = {2015}
}
In this paper, we revisit the joint probabilistic data association (JPDA) technique and propose a novel solution based on recent developments in finding the m-best solutions to an integer linear program. The key advantage of this approach is that it makes JPDA computationally tractable in applications with high target and/or clutter density, such as spot tracking in fluorescence microscopy sequences and pedestrian tracking in surveillance footage. We also show that our JPDA algorithm embedded in a simple tracking framework is surprisingly competitive with state-of-the-art global tracking methods in these two applications, while needing considerably less processing time.

MOTChallenge 2015: Towards a Benchmark for Multi-Target Tracking
L. Leal-Taixé,
A. Milan,
I. Reid,
S. Roth, and
K. Schindler
arXiv:1504.01942
bibtex |
abstract |
paper |
project page
@article{MOTChallenge2015,
title = {MOTChallenge 2015: Towards a Benchmark for Multi-Target Tracking},
shorttitle = {MOTChallenge 2015},
url = {http://arxiv.org/abs/1504.01942},
journal = {arXiv:1504.01942 [cs]},
author = {Leal-Taix\'{e}, Laura and Milan, Anton and Reid, Ian and Roth, Stefan and Schindler, Konrad},
month = apr,
year = {2015},
note = {arXiv: 1504.01942},
keywords = {Computer Science - Computer Vision and Pattern Recognition}
}
In the recent past, the computer vision community has developed centralized benchmarks for the performance evaluation of a variety of tasks, including generic object and pedestrian detection, 3D reconstruction, optical flow, single-object short-term tracking, and stereo estimation. Despite potential pitfalls of such benchmarks, they have proved to be extremely helpful to advance the state of the art in the respective area. Interestingly, there has been rather limited work on the standardization of quantitative benchmarks for multiple target tracking. One of the few exceptions is the well-known PETS dataset, targeted primarily at surveillance applications. Despite being widely used, it is often applied inconsistently, for example involving using different subsets of the available data, different ways of training the models, or differing evaluation scripts. This paper describes our work toward a novel multiple object tracking benchmark aimed to address such issues. We discuss the challenges of creating such a framework, collecting existing and new data, gathering state-of-the-art methods to be tested on the datasets, and finally creating a unified evaluation system. With MOTChallenge we aim to pave the way toward a unified evaluation framework for a more meaningful quantification of multi-target tracking.

Joint Tracking and Segmentation of Multiple Targets
A. Milan,
L. Leal-Taixé,
K. Schindler and
I. Reid
CVPR 2015
bibtex |
abstract |
ext. abstract |
paper |
video
|
project page
@inproceedings{Milan:2015:CVPR,
Author = {Anton Milan and Laura Leal-Taixé and Konrad Schindler and Ian Reid},
Booktitle = {CVPR},
Title = {Joint Tracking and Segmentation of Multiple Targets},
Year = {2015}
}
Tracking-by-detection has proven to be the most successful strategy to address the task of tracking multiple targets in unconstrained scenarios. Traditionally, a set of sparse detections, generated in a preprocessing step, serves as input to a high-level tracker whose goal is to correctly associate these “dots” over time. An obvious shortcoming of this approach is that most information available in image sequences is simply ignored by thresholding weak detection responses and applying non-maximum suppression. We propose a multi-target tracker that exploits low level image information and associates every (super)-pixel to a specific target or classifies it as background. As a result, we obtain a video segmentation in addition to the classical bounding-box representation in unconstrained, realworld videos. Our method shows encouraging results on many standard benchmark sequences and significantly outperforms state-of-the-art tracking-by-detection approaches in crowded scenes with long-term partial occlusions.
2014

Privacy Preserving Multi-target Tracking
A. Milan,
S. Roth,
K. Schindler and
M. Kudo
Workshop on Human Identification for Surveillance (HIS)
bibtex |
abstract |
paper |
video
|
slides |
project page
@INPROCEEDINGS{Milan:2014:ACCVWS,
author = {A.Milan and S. Roth and K. Schindler and M. Kudo},
title = {Privacy Preserving Multi-target Tracking},
booktitle = {Workshop on Human Identification for Surveillance},
year = {2014}
}
Automated people tracking is important for a wide range of applications. However, typical surveillance cameras are controversial in their use, mainly due to the harsh intrusion of the tracked individ- uals’ privacy. In this paper, we explore a privacy-preserving alternative for multi-target tracking. A network of infrared sensors attached to the ceiling acts as a low-resolution, monochromatic camera in an indoor en- vironment. Using only this low-level information about the presence of a target, we are able to reconstruct entire trajectories of several peo- ple. Inspired by the recent success of offline approaches to multi-target tracking [1–3], we apply an energy minimization technique to the novel setting of infrared motion sensors. To cope with the very weak data term from the infrared sensor network we track in a continuous state space with soft, implicit data association. Our experimental evaluation on both synthetic and real-world data shows that our principled method clearly outperforms previous techniques.
Improving Global Multi-target Tracking with Local Updates
A. Milan,
R. Gade,
A. Dick,
T. B. Moeslund,
I. Reid
Workshop on Visual Surveillance and Re-Identification
bibtex |
abstract |
paper |
video
|
slides
@INPROCEEDINGS{Milan:2014:IGM,
author = {A. Milan and R. Gade and A. Dick and T. B. Moeslund and I. Reid},
title = {Improving Global Multi-target Tracking with Local Updates},
booktitle = {Workshop on Visual Surveillance and Re-Identification},
year = {2014}
}
We propose a scheme to explicitly detect and resolve ambiguous situations in multiple target tracking. During periods of uncertainty, our method applies multiple local single target trackers to hypothesise short term tracks. These tracks are combined with the tracks obtained by a global multi-target tracker, if they result in a reduction in the global cost function. Since tracking failures typically arise when targets become occluded, we propose a local data association scheme to maintain the target identities in these situations. We demonstrate a reduction of up to 50% in the global cost function, which in turn leads to superior performance on several challenging benchmark sequences. Additionally, we show tracking result in sports videos where poor video quality and frequent and severe occlusion
Energy Minimization for Multiple Object Tracking
A. Milan
PhD Thesis
bibtex |
thesis |
slides |
@phdthesis{Milan:2014:EMM,
address = {Darmstadt},
type = {{PhD}},
title = {Energy Minimization for Multiple Object Tracking},
url = {http://tuprints.ulb.tu-darmstadt.de/3463/},
school = {{TU} Darmstadt},
author = {Milan, Anton},
year = {2014},
}

Continuous Energy Minimization for Multitarget Tracking
A. Milan,
S. Roth and
K. Schindler
PAMI 36(1), 2014
bibtex |
abstract |
paper |
video
|
slides |
project page
@article{Milan:2014:CEM,
author = {Milan, A. and Roth, S. and Schindler, K.},
title = {Continuous Energy Minimization for Multitarget Tracking},
volume = {36},
issn = {0162-8828},
doi = {10.1109/TPAMI.2013.103},
number = {1},
journal = {IEEE TPAMI},
year = {2014},
pages = {58--72}
}
Many recent advances in multiple target tracking aim at finding a (nearly) optimal set of trajectories within a temporal window. To handle the large space of possible trajectory hypotheses, it is typically reduced to a finite set by some form of data-driven or regular discretization. In this work we propose an alternative formulation of multi-target tracking as minimization of a continuous energy. Contrary to recent approaches, we focus on designing an energy that corresponds to a more complete representation of the problem, rather than one that is amenable to global optimization. Besides the image evidence, the energy function takes into account physical constraints, such as target dynamics, mutual exclusion, and track persistence. In addition, partial image evidence is handled with explicit occlusion reasoning, and different targets are disambiguated with an appearance model. To nevertheless find strong local minima of the proposed non-convex energy we construct a suitable optimization scheme that alternates between continuous conjugate gradient descent and discrete trans-dimensional jump moves. These moves, which are executed such that they always reduce the energy, allow the search to escape weak minima and explore a much larger portion of the search space of varying dimensionality. We demonstrate the validity of our approach with an extensive quantitative evaluation on several public datasets.
2013

Learning People Detectors for Tracking in Crowded Scenes
S. Tang,
M. Andriluka,
A. Milan,
K. Schindler,
S. Roth and
B. Schiele
ICCV 2013
bibtex |
abstract |
paper |
poster |
video
|
project page
@INPROCEEDINGS{Tang:2013:LPD,
author = {S. Tang and M. Andriluka and A. Milan and K. Schindler and S. Roth and B. Schiele},
title = {Learning People Detectors for Tracking in Crowded Scenes},
booktitle = {ICCV},
year = {2013}
}
People tracking in crowded real-world scenes is challenging due to frequent and long-term occlusions. Recent tracking methods obtain the image evidence from object (people) detectors, but typically use off-the-shelf detectors and treat them as black box components. In this paper we argue that for best performance one should explicitly train people detectors on failure cases of the overall tracker instead. To that end, we first propose a novel joint people detector that combines a state-of-the-art single person detector with a detector for pairs of people, which explicitly exploits common patterns of person-person occlusions across multiple viewpoints that are a common failure case for tracking in crowded scenes. To explicitly address remaining failure cases of the tracker we explore two methods. First, we analyze typical failure cases of trackers and train a detector explicitly on those failure cases. And second, we train the detector with the people tracker in the loop, focusing on the most common tracker failures. We show that our joint multi-person detector significantly improves both detection accuracy as well as tracker performance, improving the state-of-the-art on standard benchmarks.
Challenges of Ground Truth Evaluation of Multi-Target Tracking
A. Milan,
K. Schindler and
S. Roth
CVPR Workshop on Ground Truth
bibtex |
abstract |
paper |
poster
@inproceedings{Milan:2013:CGT,
Author = {Anton Milan and Konrad Schindler and Stefan Roth},
Booktitle = {Proc. of the CVPR 2013 Workshop on Ground Truth - What is a good dataset?},
Title = {Challenges of Ground Truth Evaluation of Multi-Target Tracking},
Year = {2013}
}
Evaluating multi-target tracking based on ground truth data is a surprisingly challenging task. Erroneous or ambiguous ground truth annotations, numerous evaluation protocols, and the lack of standardized benchmarks make a direct quantitative comparison of different tracking approaches rather difficult. The goal of this paper is to raise awareness of common pitfalls related to objective ground truth evaluation. We investigate the influence of different annotations, evaluation software, and training procedures using several publicly available resources, and point out the limitations of current definitions of evaluation metrics. Finally, we argue that the development an extensive standardized benchmark for multi-target tracking is an essential step toward more objective comparison of tracking approaches.

Detection- and Trajectory-Level Exclusion in Multiple Object Tracking
A. Milan,
K. Schindler and
S. Roth
CVPR 2013
bibtex |
abstract |
paper |
poster |
video
|
slides |
data |
project page
@inproceedings{Milan:2013:DTE,
Author = {Anton Milan and Konrad Schindler and Stefan Roth},
Booktitle = {CVPR},
Title = {Detection- and Trajectory-Level Exclusion in Multiple Object Tracking},
Year = {2013}
}
When tracking multiple targets in crowded scenarios, modeling mutual exclusion between distinct targets becomes important at two levels: (1) in data association, each target observation should support at most one trajectory and each trajectory should be assigned at most one observation per frame; (2) in trajectory estimation, two trajectories should remain spatially separated at all times to avoid collisions. Yet, existing trackers often sidestep these important constraints. We address this using a mixed discrete-continuous conditional random field (CRF) that explicitly models both types of constraints: Exclusion between conflicting observations with supermodular pairwise terms, and exclusion between trajectories by generalizing global label costs to suppress the co-occurrence of incompatible labels (trajectories). We develop an expansion move-based MAP estimation scheme that handles both non-submodular constraints and pairwise global label costs. Furthermore, we perform a statistical analysis of ground-truth trajectories to derive appropriate CRF potentials for modeling data fidelity, target dynamics, and inter-target occlusion.
2012
Discrete-Continuous Optimization for Multi-Target Tracking
A. Andriyenko,
K. Schindler and
S. Roth
CVPR 2012
bibtex |
abstract |
paper |
poster |
video |
data |
project page
@inproceedings{Andriyenko:2012:DCO,
Author = {Anton Andriyenko and Konrad Schindler and Stefan Roth},
Booktitle = {CVPR},
Title = {Discrete-Continuous Optimization for Multi-Target Tracking},
Year = {2012}
}
The problem of multi-target tracking is comprised of two distinct, but tightly coupled challenges: (i) the naturally discrete problem of data association, i.e. assigning image observations to the appropriate target; (ii) the naturally continuous problem of trajectory estimation, i.e. recovering the trajectories of all targets. To go beyond simple greedy solutions for data association, recent approaches often perform multi-target tracking using discrete optimization. This has the disadvantage that trajectories need to be pre-computed or represented discretely, thus limiting accuracy. In this paper we instead formulate multi-target tracking as a discretecontinuous optimization problem that handles each aspect in its natural domain and allows leveraging powerful methods for multi-model fitting. Data association is performed using discrete optimization with label costs, yielding near optimality. Trajectory estimation is posed as a continuous fitting problem with a simple closed-form solution, which is used in turn to update the label costs. We demonstrate the accuracy and robustness of our approach with state-of-theart performance on several standard datasets.
2011
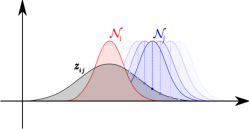
An Analytical Formulation of Global Occlusion Reasoning for Multi-Target Tracking
A. Andriyenko,
S. Roth and
K. Schindler
ICCV Workshop on Visual Surveillance
bibtex |
abstract |
paper |
poster |
video |
slides |
project page
@inproceedings{Andriyenko:2011:AFG,
Author = {Anton Andriyenko and Stefan Roth and Konrad Schindler},
Booktitle = {Proc. of the 11th International IEEE Workshop on Visual Surveillance},
Title = {An Analytical Formulation of Global Occlusion Reasoning for Multi-Target Tracking},
Year = {2011}
}
We present a principled model for occlusion reasoning in complex scenarios with frequent inter-object occlusions, and its application to multi-target tracking. To compute the putative overlap between pairs of targets, we represent each target with a Gaussian. Conveniently, this leads to an analytical form for the relative overlap – another Gaussian – which is combined with a sigmoidal term for modeling depth relations. Our global occlusion model bears several advantages: Global target visibility can be computed efficiently in closed-form, and varying degrees of partial occlusion can be naturally accounted for. Moreover, the dependence of the occlusion on the target locations – i.e. the gradient of the overlap – can also be computed in closedform, which makes it possible to efficiently include the proposed occlusion model in a continuous energy minimization framework. Experimental results on seven datasets confirm that the proposed formulation consistently reduces missed targets and lost trajectories, especially in challenging scenarios with crowds and severe inter-object occlusions.

Multi-target Tracking by Continuous Energy Minimization
A. Andriyenko and
K. Schindler
CVPR 2011
bibtex |
abstract |
paper |
poster |
video |
slides |
project page
@inproceedings{Andriyenko:2011:MTT,
Author = {Anton Andriyenko and Konrad Schindler},
Booktitle = {CVPR},
Title = {Multi-target Tracking by Continuous Energy Minimization},
Year = {2011}
}
We propose to formulate multi-target tracking as minimization of a continuous energy function. Other than a number of recent approaches we focus on designing an energy function that represents the problem as faithfully as possible, rather than one that is amenable to elegant optimization. We then go on to construct a suitable optimization scheme to find strong local minima of the proposed energy. The scheme extends the conjugate gradient method with periodic trans-dimensional jumps. These moves allow the search to escape weak minima and explore a much larger portion of the variable-dimensional search space, while still always reducing the energy. To demonstrate the validity of this approach we present an extensive quantitative evaluation both on synthetic data and on six different real video sequences. In both cases we achieve a significant performance improvement over an extended Kalman filter baseline as well as an ILP-based state-of-the-art tracker.
2010

Globally Optimal Multi-target Tracking on a Hexagonal Lattice
A. Andriyenko and
K. Schindler
ECCV 2010
bibtex |
abstract |
poster |
video
@inproceedings{Andriyenko:2010:GOM,
Author = {Anton Andriyenko and Konrad Schindler},
Booktitle = {ECCV},
Title = {Globally Optimal Multi-target Tracking on a Hexagonal Lattice},
Year = {2010}
}
We propose a global optimisation approach to multi-target tracking. The method extends recent work which casts tracking as an integer linear program, by discretising the space of target locations. Our main contribution is to show how dynamic models can be integrated in such an approach. The dynamic model, which encodes prior expectations about object motion, has been an important component of tracking systems for a long time, but has recently been dropped to achieve globally optimisable objective functions. We re-introduce it by formulating the optimisation problem such that deviations from the prior can be measured independently for each variable. Furthermore, we propose to sample the location space on a hexagonal lattice to achieve smoother, more accurate trajectories in spite of the discrete setting. Finally, we argue that non-maxima suppression in the measured evidence should be performed during tracking, when the temporal context and the motion prior are available, rather than as a preprocessing step on a per-frame basis. Experiments on five different recent benchmark sequences demonstrate the validity of our approach.
2009

A Practical Approach for Photometric Acquisition of Hair Color
A. Zinke,
M. Rump,
T. Lay,
A. Weber,
A. Andriyenko and
R. Klein
SIGGRAPH ASIA 2009
bibtex |
abstract
@inproceedings{Zinke:2009:PAP,
Author = {Zinke, Arno and Rump, Martin and Lay, Tom\'{a}s and Weber, Andreas and Andriyenko, Anton and Klein, Reinhard},
Booktitle = {ACM SIGGRAPH Asia 2009 papers},
Title = {A Practical Approach for Photometric Acquisition of Hair Color},
Year = {2009}
}
In this work a practical approach to photometric acquisition of hair color is presented. Based on a single input photograph of a simple setup we are able to extract physically plausible optical properties of hair and to render virtual hair closely matching the original. Our approach does not require any costly special hardware but a standard consumer camera only.
Code
-
Discrete-Continuous Optimization for Multi-Target Tracking
Anton Andriyenko, Konrad Schindler, and Stefan Roth. CVPR 2012
project page -
Multi-target Tracking by Continuous Energy Minimization
Anton Andriyenko and Konrad Schindler. CVPR 2011
project page -
Privacy Preserving Multi-target Tracking
A.Milan, S. Roth, K. Schindler, and M. Kudo. ACCV Workshop 2014
project page
Data
Contact
Amazon Development Center
Krausenstr. 38
10117 Berlin, Germany
E-Mail: antmila@amazon (replace amazon with amazon.com)