Data
Download all data: data-tud.zip (2.7 MB)
Ground Truth
All annotations were done by manually placing bounding
boxes around pedestrians and interpolating their trajectories between
key frames.
The trajectories were then smoothed to avoid discontinuous or jittery
movements. All
targets were annotated in all sequences, even
in case of total occlusion. Each person entering the field of view
acquires a unique ID, i.e. if a person leaves the screen and later
reappears again, a new ID is assigned. Please note that bounding boxes
are not always perfectly aligned due to articulation, interpolation
and mistakes made by the annotator.
The annotations are saved in xml files using the CVML Specification, similar to the ground truth of the CAVIAR dataset.
For each dataset there are two ground truth files. One (complete) contains annotations for all visible targets, the other one (cropped) only contains targets within the predefined tracking area used in our experiments.
Please cite our work if you use the provided ground truth.
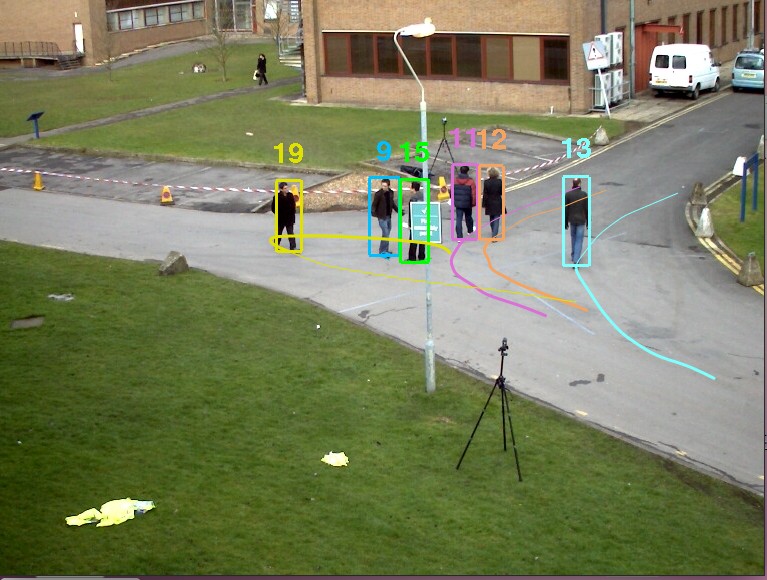
Tracking Area in world coordinates (xmin, xmax, ymin, ymax): (-14069.6, 4981.3, -14274.0, 1733.5)
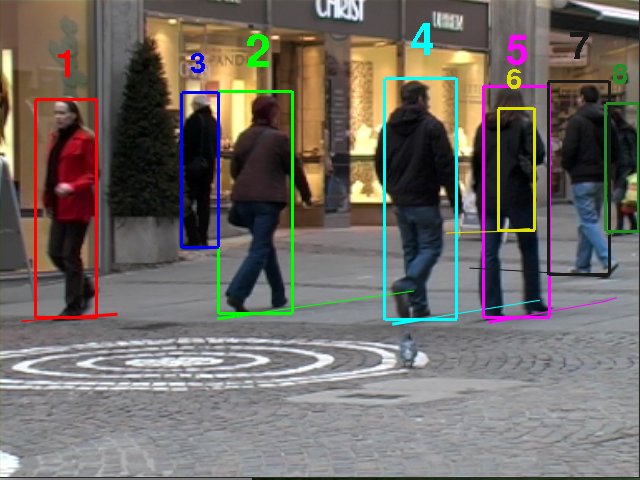
Tracking Area in world coordinates (xmin, xmax, ymin, ymax): (-19, 12939, -48, 10053)
The camera calibration for the TUD-Stadtmitte sequence is here. It has the same format as the calibration for the PETS dataset.




The annotations are saved in xml files using the CVML Specification, similar to the ground truth of the CAVIAR dataset.
For each dataset there are two ground truth files. One (complete) contains annotations for all visible targets, the other one (cropped) only contains targets within the predefined tracking area used in our experiments.
Please cite our work if you use the provided ground truth.
PETS 2009
All annotations were done in View001. The PETS 2009 dataset is available here.
Tracking Area in world coordinates (xmin, xmax, ymin, ymax): (-14069.6, 4981.3, -14274.0, 1733.5)
S2.L1 (12-34) |
S2.L2 (14-55) |
S2.L3 (14-41) |
S1.L1-1 (13-57) |
S1.L1-2 (13-59) |
S1.L2-1 (14-06) |
S1.L2-2 (14-31) |
S3.MF1 (12-43) |
|
complete cropped |
complete cropped |
complete cropped |
complete cropped |
complete cropped |
complete cropped |
complete cropped |
complete cropped |
TUD-Stadtmitte
We here provide our own annotations for the widely used TUD-Stadtmitte sequence, where bounding boxes for all targets inside the field of view (even the ones entirely occluded) are annotated. The TUD dataset is available here.
Tracking Area in world coordinates (xmin, xmax, ymin, ymax): (-19, 12939, -48, 10053)
TUD-Stadtmitte |
|
complete cropped |
The camera calibration for the TUD-Stadtmitte sequence is here. It has the same format as the calibration for the PETS dataset.
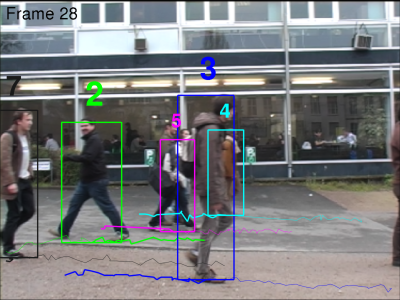
TUD-Campus and TUD-Crossing
We extend the original ground truth for these two sequences by providing correct association of people identities across frames. The bounding boxes positions and sizes are kept unchanged. Additionally, we linearly interpolate the annotations through occlusions, such that, again, all targets are annotated, regardless of their visibility fraction. TUD-Campus | TUD-Crossing |
|
original
interpolated |
original
interpolated |
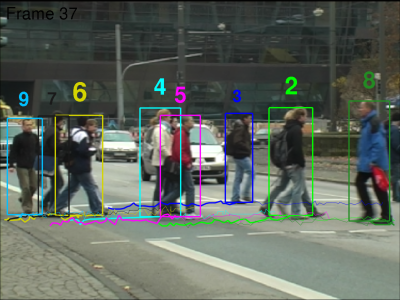
ETH-Person
Similar to TUD, we extend the original ground truth for several ETH sequences by providing correct association of people identities across frames. The bounding boxes positions and sizes are kept unchanged. The interpolated version for occluded pedestrians will appear shortly.
Sequence #0 |
Bahnhof |
Jelmoli |
Sunny Day |
|
original
interpolated |
original | original | original |
Detections
To facilitate the comparison between tracking methods, we also provide the individual detections that we use for our tracking-by-detection approach.
Similar to the ground truth data, the detection bounding boxes are stored in xml files with the only difference, that the target id is missing. Instead, the detector's confidence for each bounding box is provided.
PETS 2009
S2.L1 (12-34) |
S2.L2 (14-55) |
S2.L3 (14-41) |
S1.L1-1 (13-57) |
S1.L1-2 (13-59) |
S1.L2-1 (14-06) |
S1.L2-2 (14-31) |
S3.MF1 (12-43) |
| detections | detections | detections | detections | detections | detections | detections | detections |
TUD
Campus | Crossing | Stadtmitte |
| detections | detections | detections |
EPFL
dataset hereterrace1 | terrace2 |
|
detections c0
detections c1 detections c2 detections c3 |
detections c0
detections c1 detections c2 detections c3 |
AFL Dataset


The AFL Dataset accompanies our ECCV Workshop paper and contains the two video sequences, ground truth annotations and the detections used.
Download